
Published:
This post is a summary of Segmentation paper by Chen et al. 2016. They combine CRFs to generate a more accurate segmentation results.
Paper : Chen et al.
Challenges
There are 3 challenges in segmentation using Deep CNNs
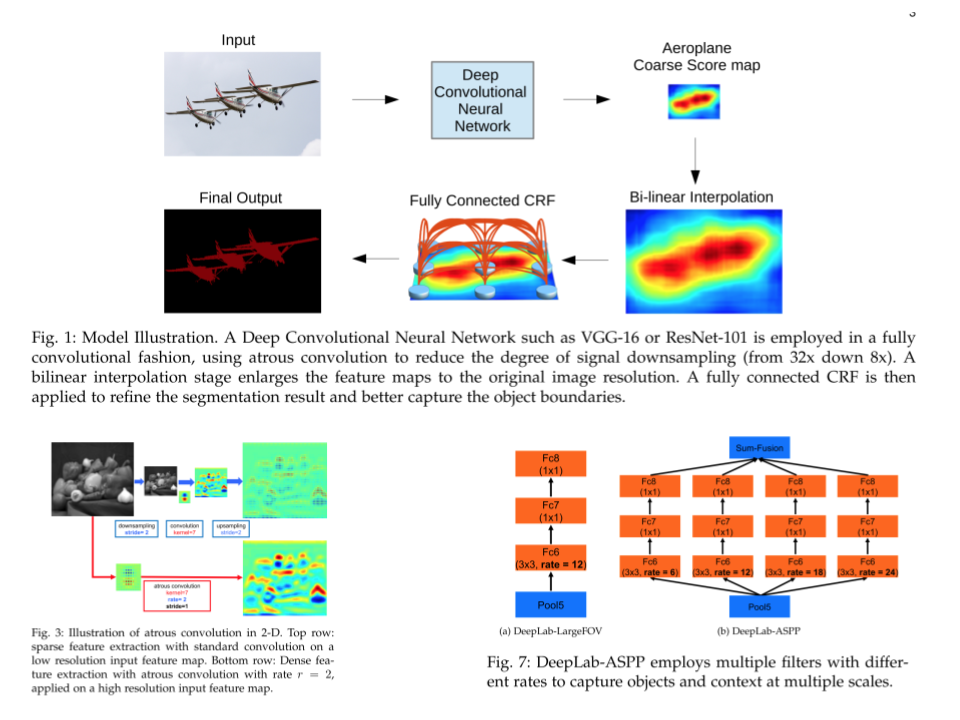
- reduced feature resolutions due to presence of multiple max-pooling and striding(downsampling). Feature maps resulting from this have reduced feature resolutions. [Solution]: instead of downsampling, use Upsampling to increase resolution in last few layers. (Atrous Convolution + bilinear interpolation) to recover original image resolution.
- multiple scales objects present in image. [Solution]: Using Atrous spatial pyramid pooling, multiple filters are used to collect complementary field of view as a result capture multiple scales, including context and object.
- presence of DCNN invariance reduces localization accuracy. [Solution]: use of fully connected CRF to assimilate fine details.
Advantages
Finally, some advantages of DeepLab
- high speed of 8 FPS.
- state-of-art accuracy.
- simple structure.
Related Works
DCNN based segmentation have following major categories
- cascade of bottom-up segmentation with DCNN based region segmentation[ 7, 49, 50]
- Coupling a convolutionally computed DCNN for image labelling and an independent segmentation. [39, 21, 51]
- segmentation free approach by computing dense category-level pixel labels.[14, 52]
Works using CRF with DCNN
- Efficient inference in fully connected crfs with gaussian edge potentials
- Combining the best of graphical models and convnets for semantic segmentation
- Learning hierarchical features for scene labeling
- Material recognition in the wild with the materials in context database
Advances in Segmentation
End-to-End training for structured prediction
Weaker Supervision based methods
- [58, 69, 70, 71] relaxes assumption of availability of pixel-level semantic annotations for training whole set.
Model Description
Leave a Comment