
Published:
Self-supervised learning consists of a learning framework designed to learn representation of data using pretext tasks. A pretext task is supervised learning setting created automatically from the input such that the cost of label is free. Read more in How? section.
Why?
A model is trained to perform at these supervised pretext tasks to get a good representation. The intermediate layers of the learned model can produce richer representation as compared to transfer learned models.
With good representation learned, the model can be used to achieve higher accuracy for usual tasks of image classification, object detection etc.
This type of learning is effective in case of partially annotated data or smaller datasets. Also, if we have access to millions of images, training in self-supervised setting will not need labeling as annotations can be generated manually.
How?
Consider a case where we rotate input image and tries to predict the rotation using a deep neural net. We can create the target rotation as the batch of data is read. As such, the only input needed are raw input images. This is an example of pretext task.
Pretext tasks are designed keeping in mind that the labels can be known on the fly using simple image transformations or permutation. There are various ways pretext tasks can be designed:
Rotation:

Example of rotation from Gidaris et al.2018
- An input image is rotated by {0, 90, 180, 270}
- model is trained to predict one of the category of rotation.
Exemplar:

Exemplar categories created by data augmentation of the top-left input image. Fig: Dosovitskiy et al. 2014
- each individual sample is considered a category.
- With this category label,multiple samples are created using augmentation technique.
- model is trained to predict the category.
Jigsaw:
- 9 patches are extracted from image and are permuted randomly within a set of 100 permutations
- Model is trained to predict the relative transformation
Following figures are taken from Noroozi and Favaro 2017

Patches are extracted from object region,

Example of a permutation of patches

Target patch orientation
Colorization:
- In this pretext task, a model takes an input a grayscale image and predicts pixel colors.
- RGB image is first converted to CIE-Lab format and Lightness channel is taken as input while ab channels are predicted.
Relative Patch Location:
- Similar to jigsaw, this task computes relative location of two patches from image.
- These location are limited to 9 , such as below, below to right etc.
- Model is trained to predict category of relative location given two patches as input.
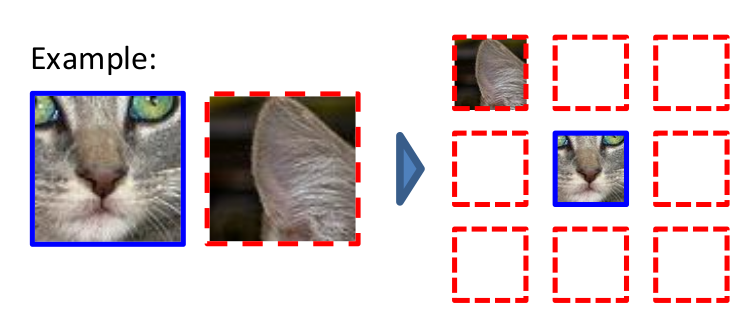
Example of relative position definition for patches as shown in
Benchmarking:
How to measure that self-supervised learning methods is actually beneficial? The comparison is established against standard supervised learning tasks.
- Learn a model using self-supervised setting with pretext tasks.
- Extract features from a labelled dataset using this model.
- Perform evaluation using transfer learning on the labelled dataset.
Results:
Attention Map Comparison:
Looking at the attention maps of Alexnet when trained using rotation pretext v/s standard supervised training. Following figures are taken from Gidaris et al. 2018

Supervised Model

Rotation based Self-supervised Model
Attention map is improved by spanning more over target region when self-supervised methods of training are used.
Effect of Network Architecture :
In the study analysis by Kolesnikov et al. several different architectures are tested with pretext tasks. A figure of analysis is as shown below
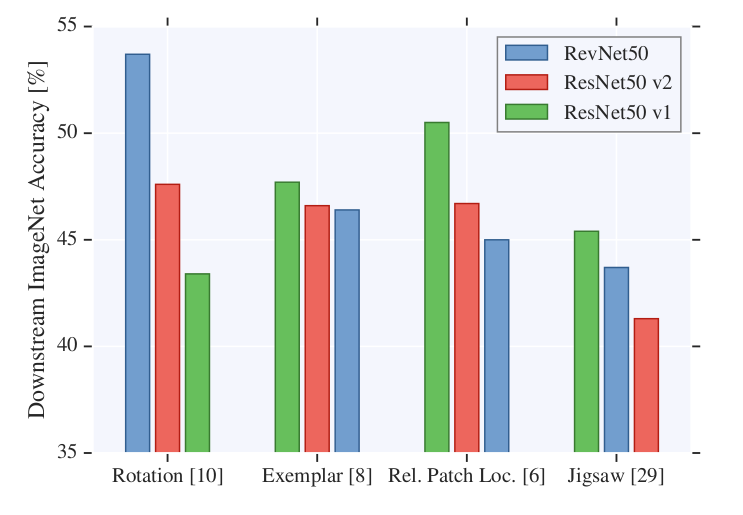
Figure by kolesnikov et al. 2019
An important conclusion, they[Kolesnikov et al. 2019] came about is:

It still cannot be considered that a pretext technique can lead to superior performance across various network architectures.
References:
- Kolesnikov, Alexander, Xiaohua Zhai, and Lucas Beyer. “Revisiting Self-Supervised Visual Representation Learning.” ArXiv:1901.09005 [Cs], January 25, 2019. http://arxiv.org/abs/1901.09005.code
- Goyal, Priya, Dhruv Mahajan, Abhinav Gupta, and Ishan Misra. “Scaling and Benchmarking Self-Supervised Visual Representation Learning.” ArXiv:1905.01235 [Cs], June 6, 2019. http://arxiv.org/abs/1905.01235.
- Noroozi, Mehdi, and Paolo Favaro. “Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles.” ArXiv:1603.09246 [Cs], August 22, 2017. http://arxiv.org/abs/1603.09246.
- Gidaris, Spyros, Praveer Singh, and Nikos Komodakis. “Unsupervised Representation Learning by Predicting Image Rotations.” ArXiv:1803.07728 [Cs], March 20, 2018. http://arxiv.org/abs/1803.07728. code
- Dosovitskiy, Alexey, Philipp Fischer, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox. “Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks.” ArXiv:1406.6909 [Cs], June 19, 2015. http://arxiv.org/abs/1406.6909.
- Doersch, Carl, Abhinav Gupta, and Alexei A. Efros. “Unsupervised Visual Representation Learning by Context Prediction.” ArXiv:1505.05192 [Cs], January 16, 2016. http://arxiv.org/abs/1505.05192.
- Blog by Lilian Weng: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
- Blog by Jeremy Howard : https://www.fast.ai/2020/01/13/self_supervised/

Leave a Comment